Q Overview
Q is data analysis and reporting software. It is chiefly used for the analysis of surveys. It seeks to perform all aspects of the analysis and reporting procedure, from data cleaning and coding through to creating tables and advanced analyses, exporting to Office and creating online reports.
The logic of Q
The way that Q works is fundamentally different to that of other data analysis programs in a number of key ways:
- Q automates most basic analyses. For example, Q will automatically determine whether to compute an average or to show a frequency table by examining the properties of the data. Similarly, Q will automatically choose the appropriate statistical test by taking into account the properties of the data (e.g., whether it is categorical, weighted, multiple response, etc.). A key consequence of this is that rather than being experts in specific analysis procedure and testing, Q users instead need to understand how to best represent their data in Q. The quality of the data file and its set up are thus key determinants of productivity.
- When a user manipulates a table in Q, the underlying data is updated to reflect that change. For example, if you drag one age group, 18 to 24, on top of another, 25 to 29, on one table, then all tables and all future tables using this data will automatically reflect this change. If you do not want to have this occur, you make multiple copies of the data (e.g., right-click on one of the age categories and select Duplicate Question). Thus, you may have two versions of age: Age and Age - All categories.
- Nearly all computations in Q are dynamic and automatically update. If you have created a report and then discover that there is an error in your data, you can correct the error in the data or replace the data file, and all the computations in the report automatically update.
Overview of the program
Starting a project
Q uses two different files: a data file, which contains the data from a market research study, and a Q Project File which stores all of your work in Q (e.g., tables you have created).
To start a project, in the File menu, select Data Sets > Add to Project > From File and then select a data file you wish to analyze in Q. You will then be prompted to either detect the file structure automatically, or to use the original file structure. It is usually appropriate to select the defaults: Automatically detect data file structure, e.g., group variables into "questions" (recommended) and (under the Advanced button) Tidy Up Variable Labels and Strip HTML from Labels. Q will then remove any repetitive text that appears in labels within a multiple response question (e.g., if the labels were Satisfaction: Citibank and Satisfaction: Bank of America, Q will replace these with Citibank and Bank of America). It will also group alike variables together to create questions.
If you already have a project open and you want to start a new one, first select File > New Project.
The Tables, Variables and Questions, Data and Notes tabs
When you start Q, you are in the Outputs Tab; this is where most data analysis is performed. Tables are created by selecting questions from the Blue and Brown Drop-down Menus and more advanced analyses are run by selecting them in the Create menu or from the Browse Online Library option in the Automate menu.
All tables shown in the Outputs Tab are formed from questions. The precise way that Q computes a table is determined by the Question Types of the questions being analyzed and their Value Attributes (i.e., which values are treated as missing, any recoding, which values are to be counted when computing percentages). Question Types and Value Attributes and most metadata are edited in the Variables and Questions tab. Change tab by clicking on the tabs at the bottom left of the screen (![]() ).
).
The raw data can be viewed in the Data tab. Any changes that are made to the raw data are applied to the data before any changes made in the Variables and Questions tab and these are, in turn, made prior to changes made on the Outputs Tab.
Notes can be written in the Notes tab.
Saving and opening projects
Projects are saved using either Save or Save As in the File menu. Once you have saved a project, re-open it by selecting Open > Existing Project from the File menu. That is, while a project is started by importing a data file, once the project has been started you do not need to import the data again. Q will automatically read the data file associated with your project.
All of your work is saved as a Q Project File, which has a file extension of .Q. Q makes no modifications to the underlying data itself, and this makes it easy to update reports with new data.
The data hierarchy
Within Q there are a variety of places where a user can modify the data. These places are ordered in the following hierarchy:
- The raw data file. Where the raw data is changed, all analyses that refer to the data will automatically update.
- The Data tab. Changes made in the Data tab do not modify the raw data file, but do flow through to everything else in Q.
- The Variables and Questions tab and Value Attributes. Although changes to data in these places is visible on the Data tab, changes made on the Data tab have precedence over changes made here, regardless of the order in which the changes have been made. For example, if the user has used Value Attributes to recode all values of 9 in a variable as -9s this will shown on the Data tab as
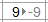 . However, if the user clicks into the cell to edit the data on the Data tab, a value of 9 will be shown in the cell. And, if the user manually changes this value from 9 to 8, it is this value of 8 that will be used in all subsequent calculations, as the Value Attributes-based recoding of 9s to -9s is no longer applicable, as the cell no longer contains the value of 9.
. However, if the user clicks into the cell to edit the data on the Data tab, a value of 9 will be shown in the cell. And, if the user manually changes this value from 9 to 8, it is this value of 8 that will be used in all subsequent calculations, as the Value Attributes-based recoding of 9s to -9s is no longer applicable, as the cell no longer contains the value of 9. - The Outputs Tab. For example, if a user modifies a label on the Outputs Tab it will not update what is shown on the Variables and Questions tab or on the Data tab, whereas a change in the Label on the Variables and Questions tab or in the Value Attributes will flow through to the Data tab. Note that there are some shortcuts on the Outputs Tab that can be used to modify the Variables and Questions tab and Value Attributes, but this does not change the hierarchy (i.e., the changes are, from a precedence perspective, viewed as occurring in the Variables and Questions tab and the Value Attributes form, even if these were accessed from the Outputs Tab).
See also
- The Main Page of this wiki.
- Overview of Statistical Testing in Q.
- Navigating Around Q.
Further reading: Data Analysis Software